Building Agentic applications using Agentcore
Over the last few months I spent a lot of time experimenting with AWS AgentCore and comparing it with frameworks like CrewAI and LangGraph
Initially I thought AgentCore was simply another managed AI service from AWS. But after building a few proof of concepts and reviewing the architecture deeply, I realized AWS is trying to solve something much bigger
They are slowly building a full operating system for AI agents ☁️.Honestly, once you start building real multi-agent systems, you quickly realize why this direction makes sense
The difficult part is not the LLM anymore. The difficult part is:
- memory
- orchestration
- governance
This blog is basically my understanding of how modern agentic systems are evolving and where AWS AgentCore fits into that picture
The First Big Problem: Memory 🧠
Most AI demos look impressive during the first interaction. Then the second interaction happens 😄
The system forgets context
The agent loses state
The workflow starts hallucinating
That is when you realize memory is one of the hardest problems in agentic AI . A proper AI agent usually needs multiple kinds of memory working together
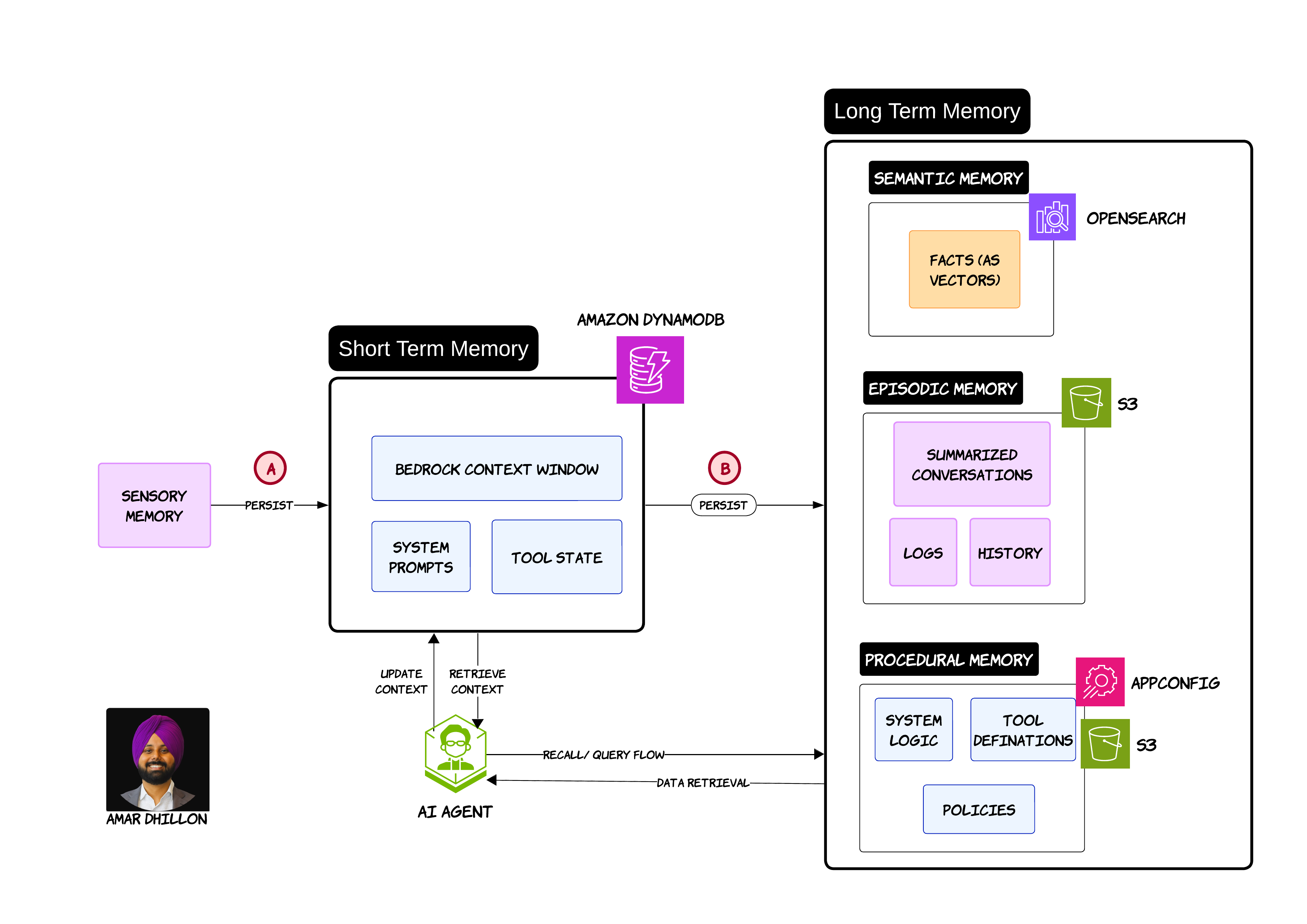
The way I usually explain this is:
- short-term memory handles active conversations
- long-term memory stores durable knowledge
- procedural memory stores system behavior
This sounds simple on paper but becomes very interesting in production systems
Short-Term Memory
Short-term memory is basically the working memory of the agent
This is where the active context lives:
- user prompts
- system prompts
- tool states
In most systems this is closely tied to the model context window. You can think of it like temporary RAM for the agent
In the diagram above, the short-term layer is backed by DynamoDB and constantly updated while the user interacts with the AI system. One thing I learned very early is that short-term memory grows extremely fast in enterprise workflows
A simple chatbot conversation is manageable. But once agents start:
- calling tools
- invoking APIs
- collaborating with other agents
The context explodes very quickly
Context windows are not infinite
Many teams treat the LLM context window like unlimited memory.
Eventually token limits and latency become serious problems
Long-Term Memory
Long-term memory is where things become much more interesting. This memory survives beyond the current session
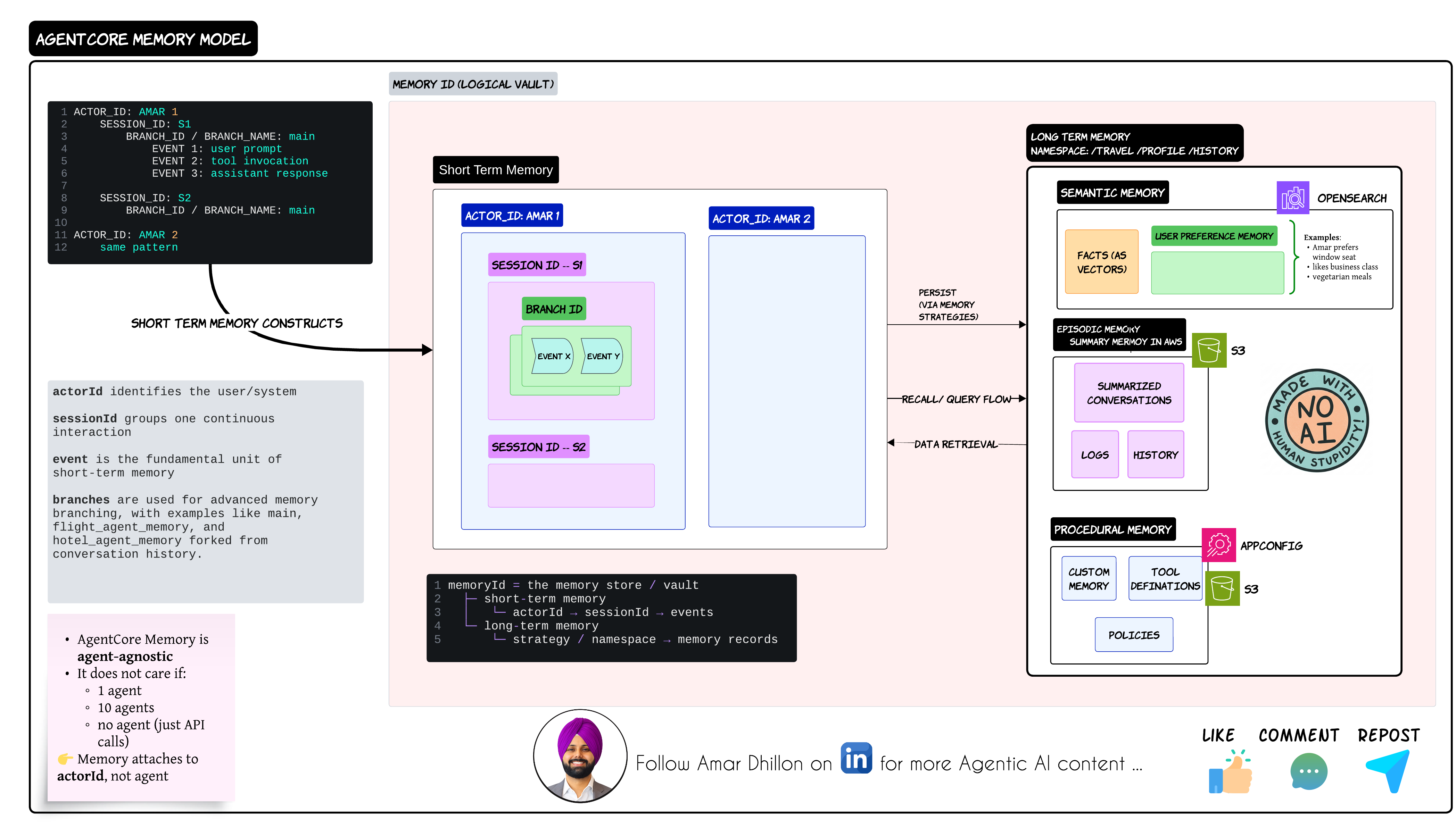
The diagram above shows one of the cleanest ways to think about memory separation in agentic systems. The long-term layer itself usually gets divided into:
- semantic memory
- episodic memory
- procedural memory
Semantic Memory
Semantic memory stores facts and knowledge. This is usually vectorized and stored inside systems like OpenSearch
Examples:
- customer preferences
- business rules
- enterprise facts
A customer support agent may remember:
customer prefers email communication
Or:
user usually books business class
That memory becomes reusable across future interactions
Episodic Memory
Episodic memory stores conversation history and experiences. This is where summarized interactions and historical flows live
In many architectures this ends up inside S3 because the volume grows rapidly over time. I personally think episodic memory is heavily underrated right now
It becomes extremely useful for:
- personalization
- audit trails
- agent replay
Procedural Memory
Procedural memory is very different. This memory stores:
- policies
- workflows
- tool definitions
This is basically the operational behavior of the system. In enterprise environments this layer becomes extremely important because governance teams usually care more about process consistency than raw LLM intelligence 😄
Important distinction
RAG is retrieval.
Memory is persistence and evolving state over time
AWS AgentCore Starts Making More Sense 🏗️
Once memory and orchestration become complicated, you start realizing why AWS introduced AgentCore
At a high level, AgentCore is trying to provide managed building blocks for enterprise-grade agentic systems
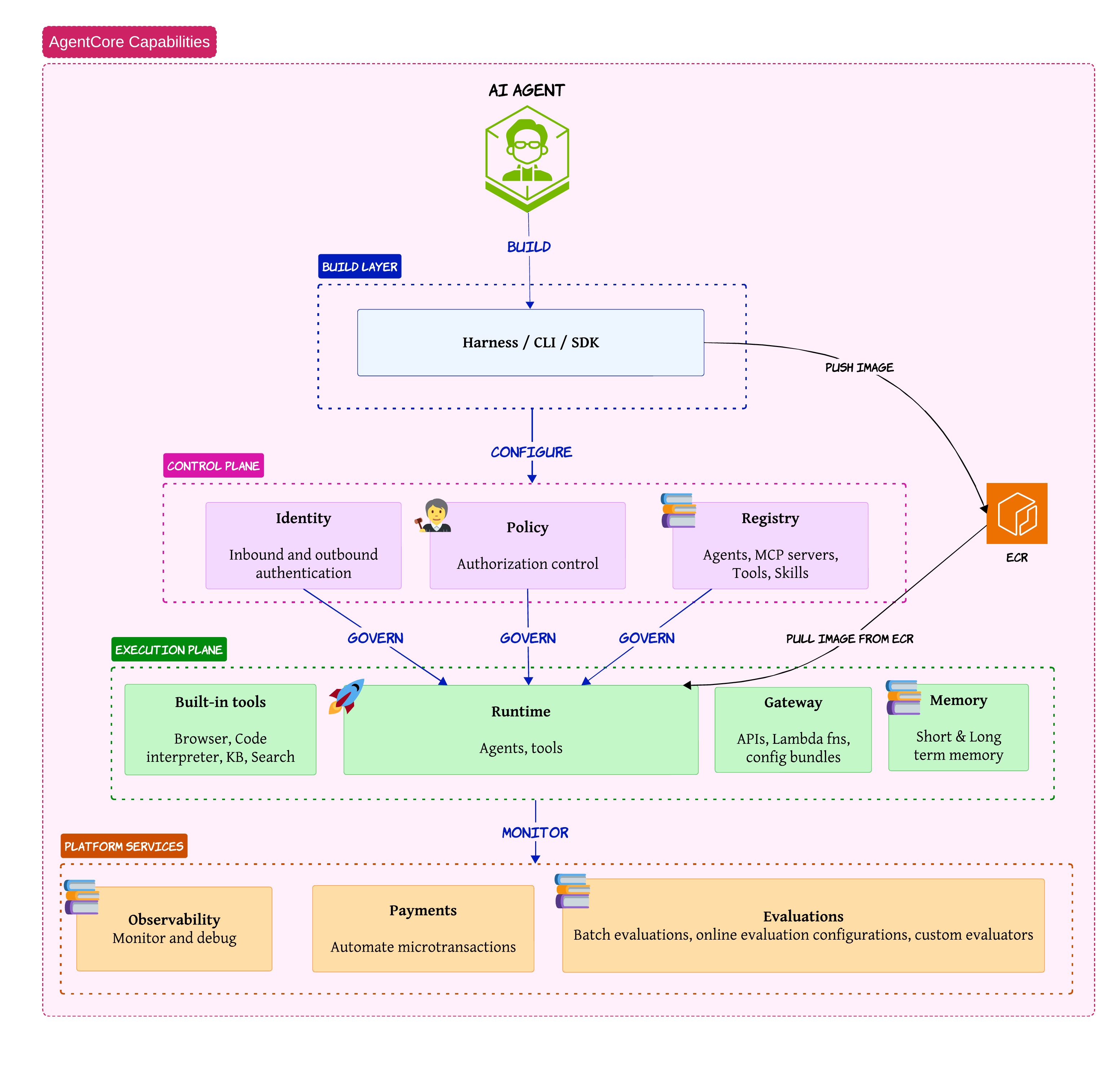
The architecture is actually pretty elegant once you break it down into layers
You have:
- build layer
- control plane
- execution plane
- platform services
Build Layer
The build layer is where developers create and package agents. This is where SDKs and harness frameworks operate
The built artifacts eventually get pushed into ECR. That part immediately reminded me of how containerized microservices evolved a few years ago
Agents are slowly becoming deployable runtime artifacts
Interesting shift
We are slowly moving from "prompt engineering" toward "agent lifecycle management"
Control Plane
The control plane is probably one of the most important parts of AgentCore. This layer handles:
- identity
- policy
- registry
The registry concept is extremely important because modern AI systems may eventually have:
- agents
- MCP servers
- tools
all dynamically discoverable inside the ecosystem
The identity layer controls inbound and outbound authentication while the policy layer controls authorization boundaries. This becomes very important once autonomous agents start interacting with enterprise systems
Execution Plane
The execution plane is where the actual runtime behavior happens
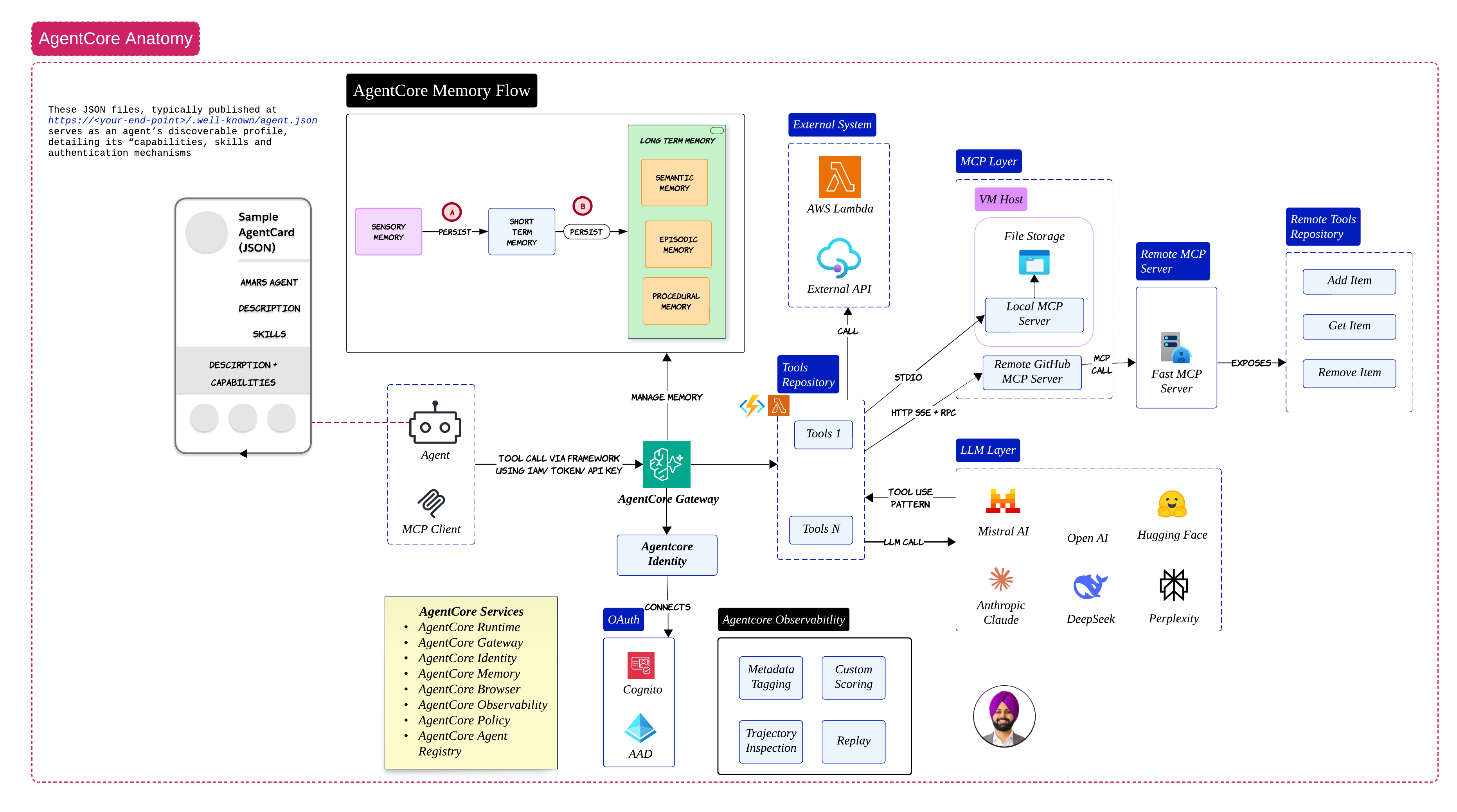
This diagram is probably one of my favorite ways to visualize AgentCore internally
The runtime becomes the operational heart of the system
It interacts with:
- memory
- gateways
- MCP servers
- external tools
One thing I liked here is the separation between local MCP servers and remote MCP servers. This creates a very clean abstraction model for tool access
The AI agent itself does not need direct awareness of underlying infrastructure complexity. Instead, the agent interacts through standardized interfaces
That separation becomes incredibly useful for governance and scalability
Big enterprise challenge
Tool governance becomes much harder than prompt governance once agents start executing actions
MCP and Tool Access 🔌
One thing becoming increasingly obvious across the industry is this:
Agents need standardized access to tools. Without standardization, every framework creates its own integration model and eventually the architecture becomes messy
The MCP layer in AgentCore solves a very important problem:
- tool discovery
- tool invocation
- tool isolation
This starts making agent ecosystems much more modular. A GitHub MCP server can expose repository operations
A database MCP server can expose query operations. The AI agent only needs to understand capabilities and not infrastructure internals
That is a massive architectural improvement
Agent Memory Flow
The memory flow inside AgentCore is actually very elegant once you visualize it properly
Sensory memory first enters the short-term layer. Then selected information gets persisted into long-term memory strategies
That persistence path is extremely important because not everything should become permanent memory. If every interaction becomes persistent memory:
- costs increase
- retrieval quality decreases
- hallucinations become worse
Good memory engineering is often about deciding what NOT to remember 😄
Multi-Agent Patterns 🤖
As systems become larger, single-agent architectures start becoming limiting. That is where orchestration patterns become useful
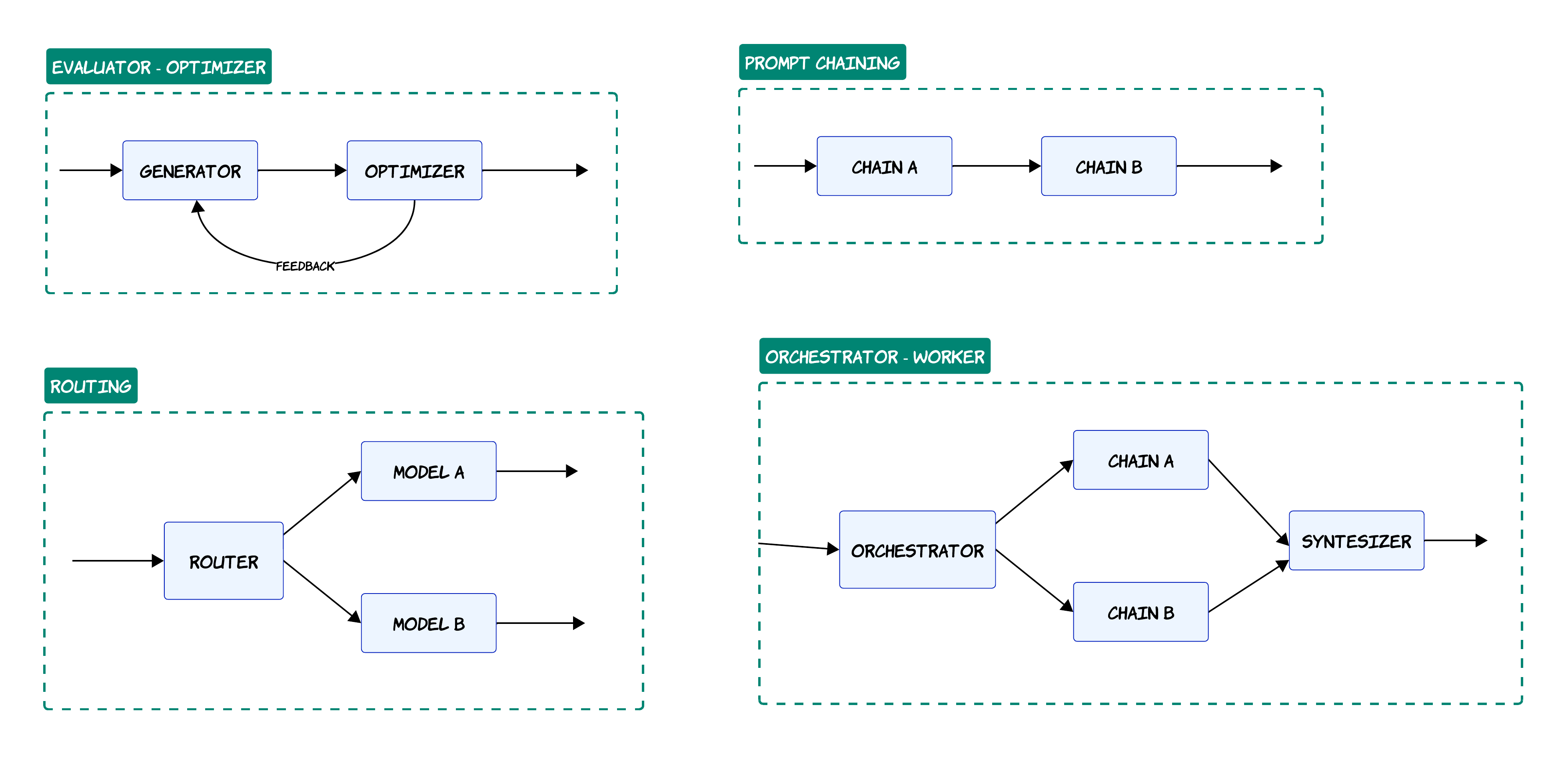
Some patterns I repeatedly see in production systems are:
Prompt Chaining
One agent produces output and another agent refines it. This is one of the safest patterns because control flow remains predictable
Routing
A lightweight router selects the correct model or chain based on task complexity. This is extremely useful for cost optimization
Not every request needs GPT-5 level reasoning 😄
Orchestrator-Worker
This is probably my favorite enterprise pattern
A supervisor agent delegates specialized work to multiple worker chains and then synthesizes the final response. This pattern maps extremely well to:
- customer service
- enterprise search
- operational workflows
Evaluator-Optimizer
This pattern becomes powerful when paired with evaluations
One component generates while another critiques and improves. This starts resembling iterative reasoning systems
Production reality
Simpler orchestration patterns are usually more stable than overly autonomous systems
CrewAI vs LangGraph vs AgentCore ⚔️
A question I get a lot is:
Which framework should we choose?
Honestly, they solve different problems
CrewAI
CrewAI feels very natural when building collaborative agent systems
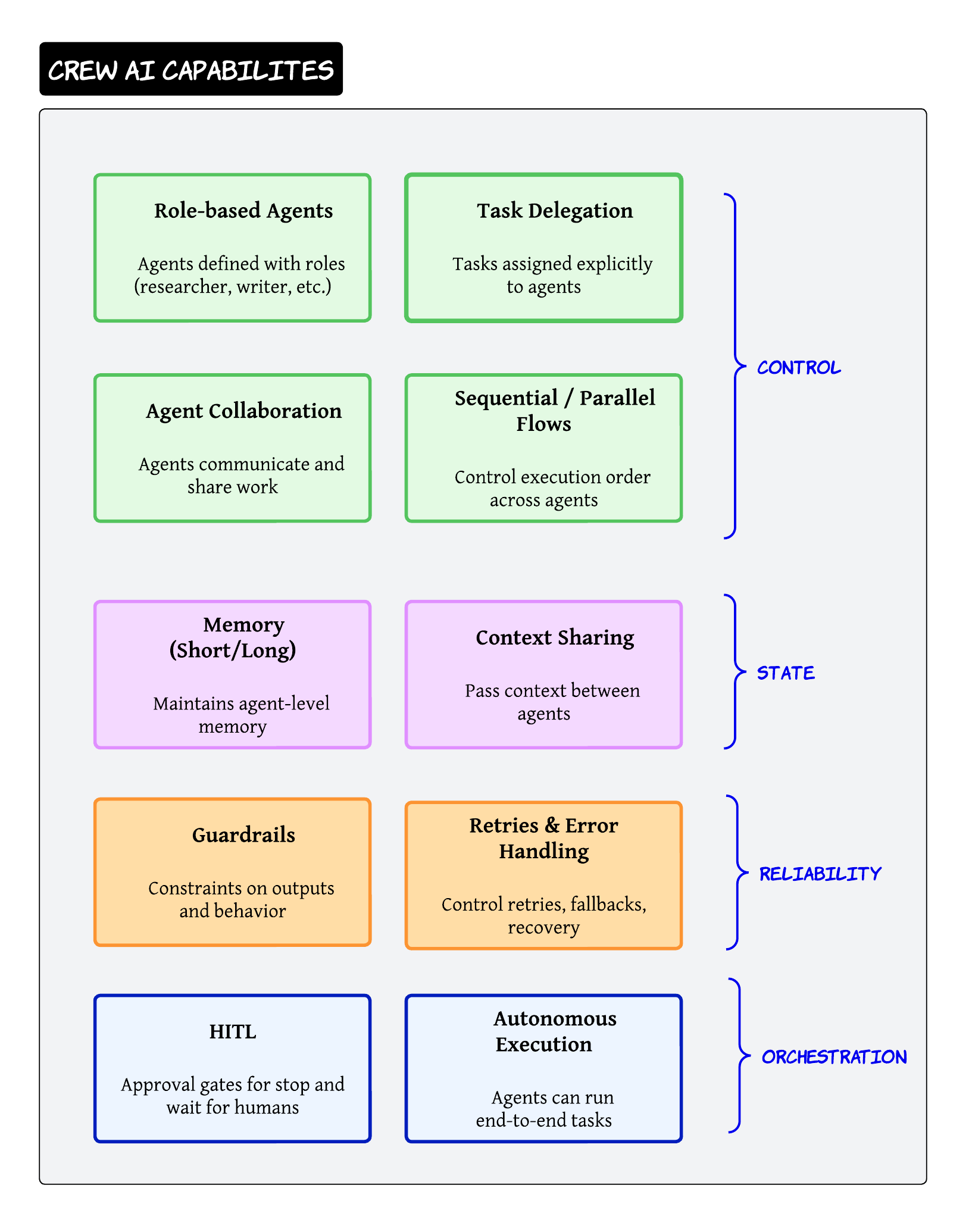
The framework focuses heavily on:
- role-based agents
- delegation
- collaboration
It feels intuitive because the architecture resembles human teams
You define:
- researcher agent
- writer agent
- reviewer agent
Then coordinate workflows between them. CrewAI is very good for fast experimentation and collaborative workflows
I personally think it is one of the easiest frameworks for demonstrating multi-agent concepts quickly
LangGraph
LangGraph feels much more deterministic and engineering-oriented
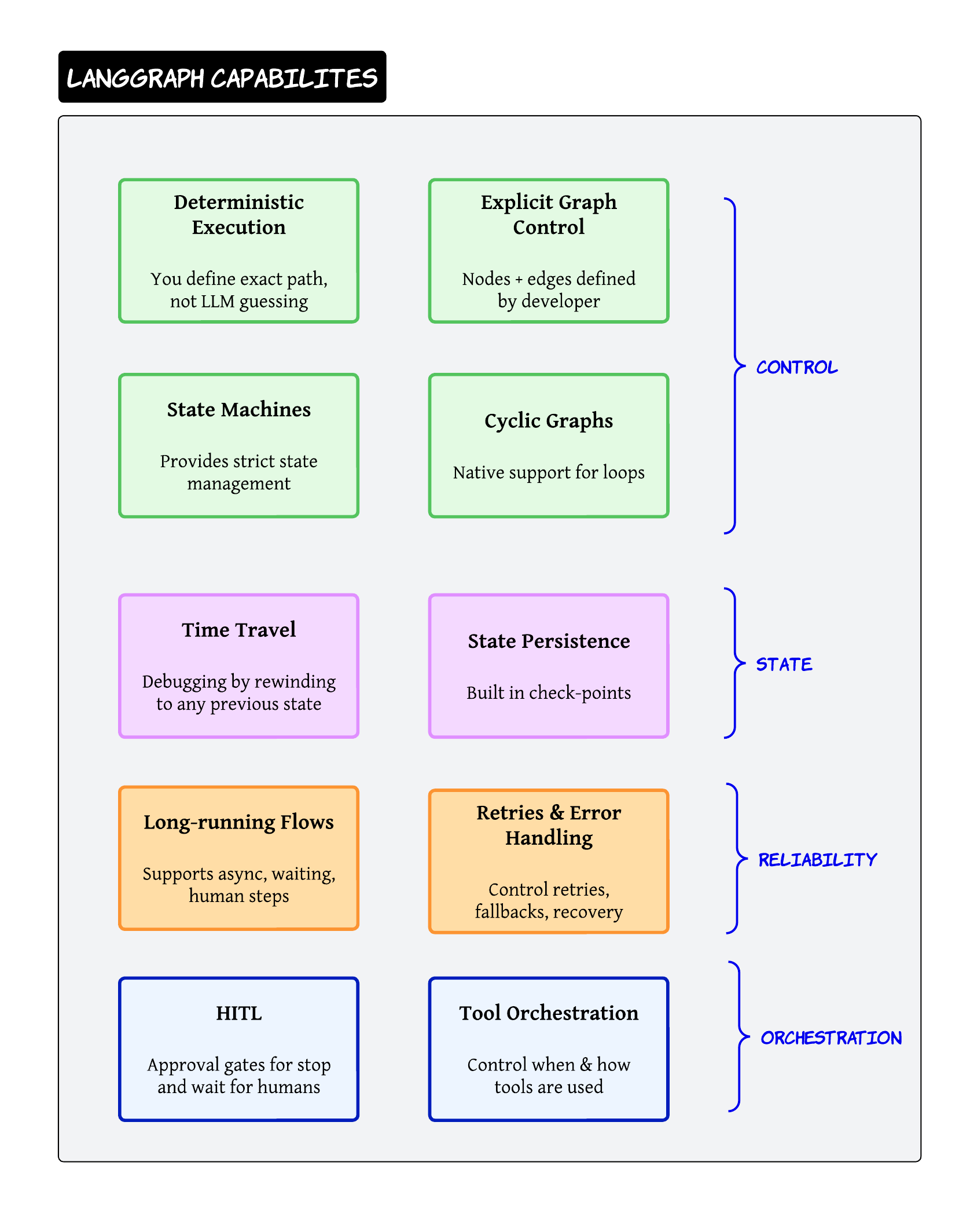
This framework focuses heavily on:
- state management
- graph execution
- reliability
What I really like about LangGraph is explicit control. The developer controls nodes, edges and execution flow directly
This makes it extremely useful for: - long-running workflows - HITL systems - checkpointing
The time-travel debugging capability is honestly very powerful for enterprise troubleshooting
My practical view
CrewAI feels closer to collaborative reasoning.
LangGraph feels closer to workflow orchestration engineering
Where AWS AgentCore Fits
This is where things become interesting
AgentCore is not really trying to replace CrewAI or LangGraph completely. Instead, AWS appears to be building the enterprise runtime layer around these patterns
You can still use:
- CrewAI
- LangGraph
- custom orchestrators
But AgentCore tries to provide:
- governance
- observability
- identity
- runtime services
This is actually a smart strategy from AWS
Because enterprises usually care more about:
- Security
- Auditability
- Scalability
than framework popularity itself
Final Thoughts 🚀
The industry is slowly moving beyond simple chatbots. We are entering a phase where AI systems behave more like distributed software platforms with:
- Memory
- Orchestration
- Governance
Honestly, I think memory architecture will become one of the biggest differentiators in future agentic systems, Not model size or the prompt engineering
Memory quality and orchestration quality. AWS AgentCore is interesting because it acknowledges this reality directly. Instead of focusing only on models, it focuses on the operational ecosystem around agents. I think that is exactly where enterprise AI is heading next

